![东莞股票配资平台官网 [专家视角]华东理工大学/井冈山大学周彦波团队SPT综述: 机器学习在重金属吸附建模中的应用研究](/uploads/allimg/250816/161614140106327.jpg)
 东莞股票配资平台官网
东莞股票配资平台官网
第一作者:赵姝彦
通讯作者:周彦波
通讯单位:含碳废弃物资源化零碳利用教育部工程中心,上海,200237;生命科学学院,红壤区功能生物与污染治理江西省重点实验室,井冈山大学,吉安,343009;煤液化、气化与高效低碳利用国家重点实验室,上海,200237
图片摘要
亮点
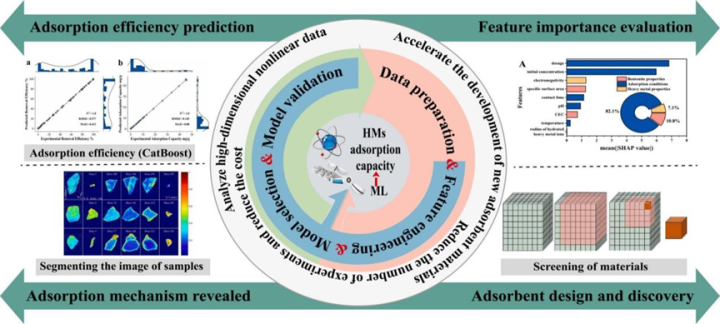
近日,周彦波教授研究团队在环境领域期刊SeparationandPurificationTechnology上发表了题为“Applicationsofmachinelearninginheavymetaladsorptionmodeling:Areview”的综述论文。本文系统梳理了机器学习在重金属吸附领域从建模到应用的最新研究进展,全面概述了吸附建模的核心流程,重点聚焦于机器学习技术在吸附效率预测、特征变量重要性评估以及吸附机制解析等方面所展现出的关键作用。值得注意的是,本文深入分析了吸附效率预测模型选择策略的演变过程,并探讨了影响模型性能的关键参数识别方法。同时,研究表明,机器学习在吸附剂的结构优化与设计中也发挥了重要的推动作用。最后,本文还针对当前机器学习在吸附建模应用中所面临的主要挑战进行了深入剖析,并提出了未来的研究方向,特别强调了其在实际工程中的可实施性与应用潜力。
引言
工业废水与采矿活动导致重金属在水体中富集,通过食物链引发人类神经毒性或生殖损伤。相较于成本高、易产生二次污染的传统方法,吸附技术因成本低、可再生性脱颖而出,但其研究面临高维非线性挑战:实验难以同步调控pH、初始浓度等多参数,传统等温线模型(Langmuir/Freundlich)需简化假设。ML通过挖掘多维数据潜在关联,在重金属吸附领域展现出巨大潜力。
进一步研究发现,集成学习(如随机森林)通过“多模型投票”降低误差,深度学习(DL)则可以通过神经网络自动提取特征,尤其适合复杂机理建模。然而机器学习普遍存在的“黑箱”问题制约其应用,XAI技术通过可视化决策过程(如SHAP值分析)增强物理可解释性。尽管已有ML在吸附领域的零星综述,但尚缺乏系统性、前瞻性的综述。为此,本文构建完整建模流程框架,覆盖从机器学习预测吸附材料性能到辅助材料逆向设计的闭环。
图文导读
机器学习应用于重金属吸附建模流程
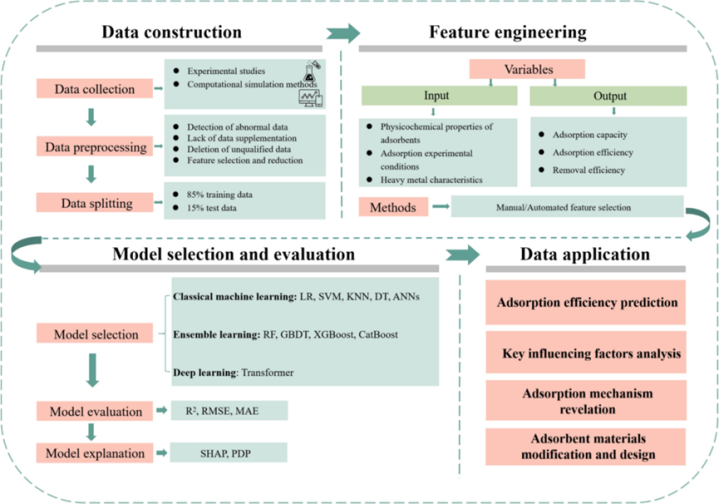
ML建模需三大步骤:
数据准备:
数据准备是建模的基础,主要包括数据收集和数据预处理两个环节。在数据收集阶段需要整合吸附剂特性(比表面积、官能团)、环境参数(pH、离子强度)及性能指标(Qe)。
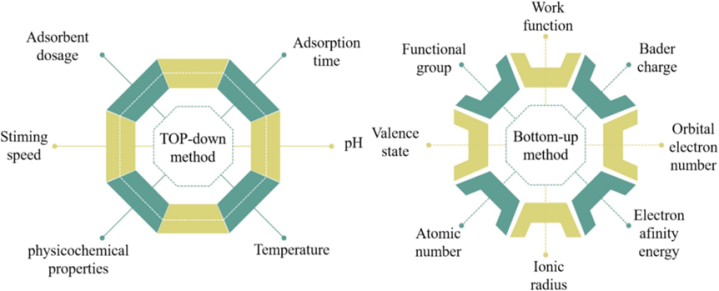
数据来源主要包括两类:
文献提取(自上而下):常用方法,获取真实实验数据,不受计算资源限制,且“失败实验”数据同样具有重要参考价值;
计算模拟(自下而上):如DFT和分子动力学,适用于大规模数据生成,但计算复杂、跨学科要求高。
原始数据往往存在缺失、噪声和不一致等问题,需通过插值、异常值处理和归一化等手段进行严格预处理,以提升模型稳定性和准确性。深度学习可进一步简化特征提取流程,降低人工干预。
特征工程:
特征工程的作用是从原始数据中构建出有助于模型学习和预测的特征,传统方法依赖人工选择特征,效率低且受经验影响。随着深度学习的发展,自动特征提取成为趋势,显著减少了人工干预。
模型选择与验证:
机器学习算法的选择取决于数据集规模、性质及目标变量类型。传统算法主要分为监督学习与无监督学习:前者适用于标记数据,可构建回归或分类模型;后者用于未标记数据。半监督学习介于二者之间,训练集由少量标记样本与大量未标记样本组成。
本研究结合现有研究,总结重金属吸附建模中的可行方法。研究表明该领域算法应用已从经典统计学习发展到深度学习。早期因实验数据有限,多采用基础建模技术;随着高维吸附动力学、热力学及微观结构数据的积累,集成学习与深度学习已成为性能预测与机理探索的核心手段。
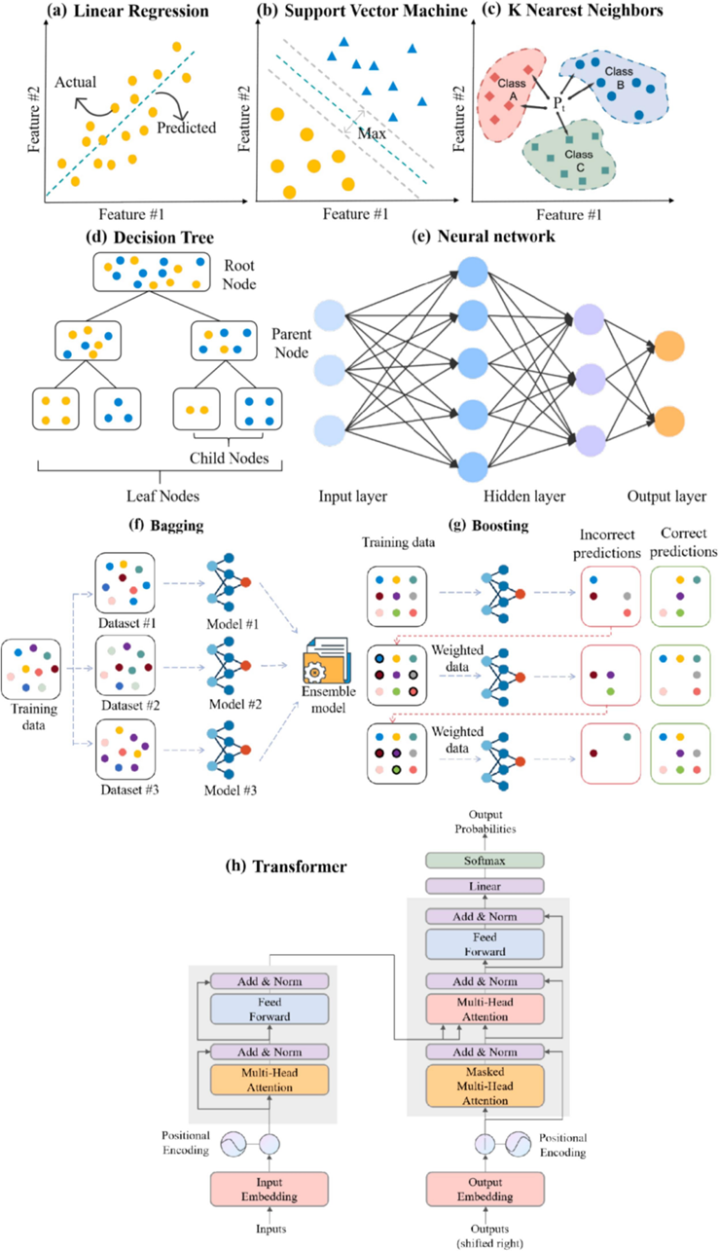
图3:重金属吸附建模中常用的算法模型。经典机器学习算法:(a)线性回归;(b)支持向量机;(c)K最近邻;(d)决策树;(e)神经网络。集成学习算法:(f)Bagging;(g)Boosting。深度学习算法:(h)Transformer。
模型训练完成后,需通过独立的测试集进行验证,评估其预测准确性。应根据具体任务选择合适且公正的评估指标。通过k折交叉验证避免过拟合,优先选择R2>0.9的算法。
机器学习在重金属吸附建模中的应用
1、吸附效率预测
传统方法依赖吸附等温线模型,局限于经验公式、实验数据积累,且难以处理复杂系统的高维与非线性特征,而ML(如梯度提升树)可同时纳入10+变量,预测误差降低20%~40%。
现有研究中,数据量普遍较小且不明确。常用的高性能模型包括人工神经网络和集成学习模型,其R²多高于0.95,深度学习仍处于探索阶段。总体而言,各模型在不同条件下各有优势,尚无统一评价标准。传统Langmuir模型仅描述Qe-Ce关系,而ML(如梯度提升树)可同时纳入10+变量,预测误差降低20%~40%。
2、特征重要性评估
重金属吸附效率受吸附剂理化性质、金属离子特性及实验条件的共同影响。识别关键影响因素有助于优化吸附系统并提升污染修复效果。传统单因素设计法虽简便,但难以揭示变量间复杂关系。相比之下,机器学习可有效评估特征重要性,弥补传统方法不足。可解释性技术如SHAP和PDP增强了模型透明度,SHAP量化特征对预测结果的正负贡献,PDP展示特征与结果的函数关系。
3、吸附机理揭示
污染物与吸附材料的相互作用受其理化性质影响,吸附机理可分为物理吸附和化学吸附。传统方法如动力学模型、等温线模型和表征技术(FTIR、SEM、XRD等)为研究提供了基本理解,但通常只能推测相互作用机制。机器学习通过特征重要性评估,为吸附过程提供了新的视角,有助于深入分析吸附剂与重金属离子之间的相互作用。
4、吸附剂材料的设计与发现
机器学习在处理复杂数据和挖掘潜在规律方面具有显著优势,因而逐渐成为材料设计领域的重要辅助工具。在吸附材料研究中,机器学习的主要应用包括两方面:
(1)高通量筛选与性能预测:通过训练模型揭示材料结构与吸附性能之间的内在关系,从而快速筛选潜在候选材料并指导优化设计。例如,Yuan等人结合几何分析与随机森林方法,从14万余个MOF中筛选出10种对Pb(II)具有高效吸附能力的材料,并进一步发现羧基是影响其吸附性能的关键结构特征。
(2)逆向设计:借助机器学习,可根据目标性能反推最佳材料组成与结构参数,实现高效研发并显著降低成本。
小结与展望
本文系统地回顾了机器学习技术在重金属吸附中的一般工作流程,讨论了其在吸附材料性能预测、特征重要性评估、吸附机理揭示以及吸附材料设计方面的应用。机器学习在建模过程、性能预测和材料设计方面的巨大潜力和优势。然而,仍有进一步进步的机会。提出了加强机器学习在重金属吸附应用的几个未来方向。
(1)构建标准化吸附数据库:统一实验数据,提升模型准确性与可复用性。
(2)发展集成深度学习算法:结合深度学习与集成学习,提升预测精度与特征提取能力。
(3)融合理论科学知识:引入基于物理的建模约束,增强模型的可解释性与物理一致性。
作者简介

周彦波:华东理工大学/井冈山大学教授、博导、国家高层次青年人才,上海市课程思政教学名师、上海市东方学者、上海市优秀技术带头人,入选ScholarGPS全球前0.05%顶尖学者榜单。担任ChineseChemicalLetters、FrontiersofEnvironmentalScience&Engineering等期刊编委,长期致力于废水处理与资源化、化工过程减污降碳协同技术研究。发表论文140余篇、ESI高被引论文20篇,兼任上海市环境科学学会水环境专业委员会副主任委员。
第一作者:赵姝彦,女,硕士研究生,现就读于华东理工大学资源与环境工程学院。
文章链接:https://doi.org/10.1016/j.seppur.2025.134168东莞股票配资平台官网
广盛配资提示:文章来自网络,不代表本站观点。




